What we learned building a 100M-document search engine, part 2: ANN Tuning
We tuned ANN indexing, query embeddings, and quantization across 100 million documents. The components interact in ways benchmarks do not predict.
Janne Beate Bakeng & Elisabeth Koren Halvorsen··7 min read
This is Part 2 of a three-part series on building and evaluating large-scale retrieval.
Part 1covered the operational reality of working at this scale. This post covers what happened when we started running queries. Part 3 examines what happens when semantic and lexical retrieval are combined across different query types.
In Part 1, we described the iteration cost of running experiments at 100 million documents: 27 to 30 hours per reindex before we could evaluate a single configuration change.
We expected this experiment to be straightforward: Run queries. Measure recall. Tune index parameters. Write up the results.
It did not go that way.
91% Short Documents
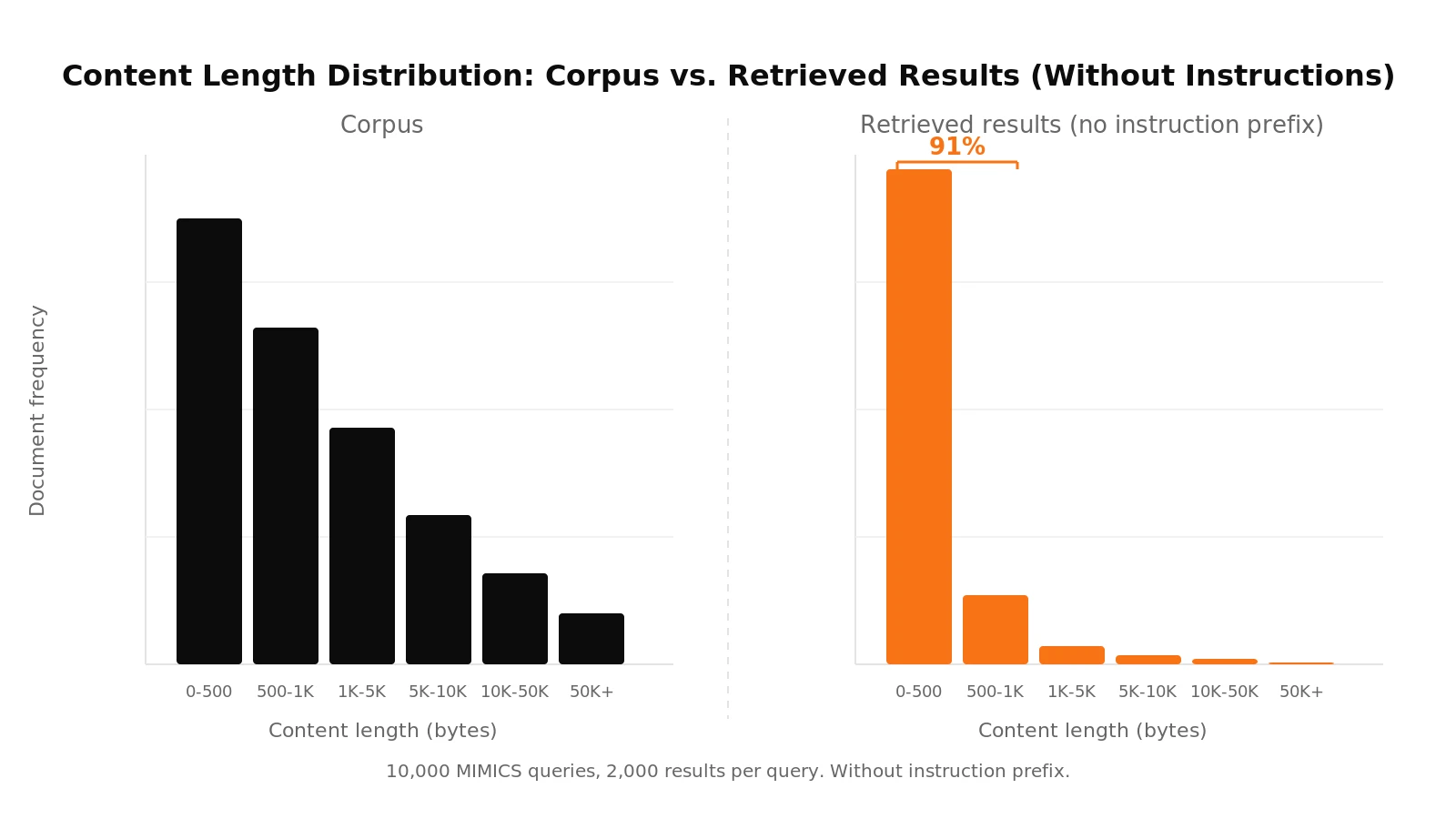
Before running our experiments, we wanted to verify that retrieval was behaving sensibly. We ran 10,000 queries from MIMICS , a dataset of real human search queries, and retrieved 2,000 results per query. Then we looked at what came back.
Every document in our corpus has a content length field representing its size in bytes. The corpus follows a long-tail distribution: most documents are short, but there is meaningful mass across the full range. If retrieval is working correctly, the distribution of results should roughly reflect the distribution of the corpus.
It did not. 91% of the retrieved documents had a content length under 1,000 bytes. The corpus distribution was nowhere to be seen. Short documents were not just overrepresented; they were almost the only thing coming back.
The Embedding Model Expected Instructions
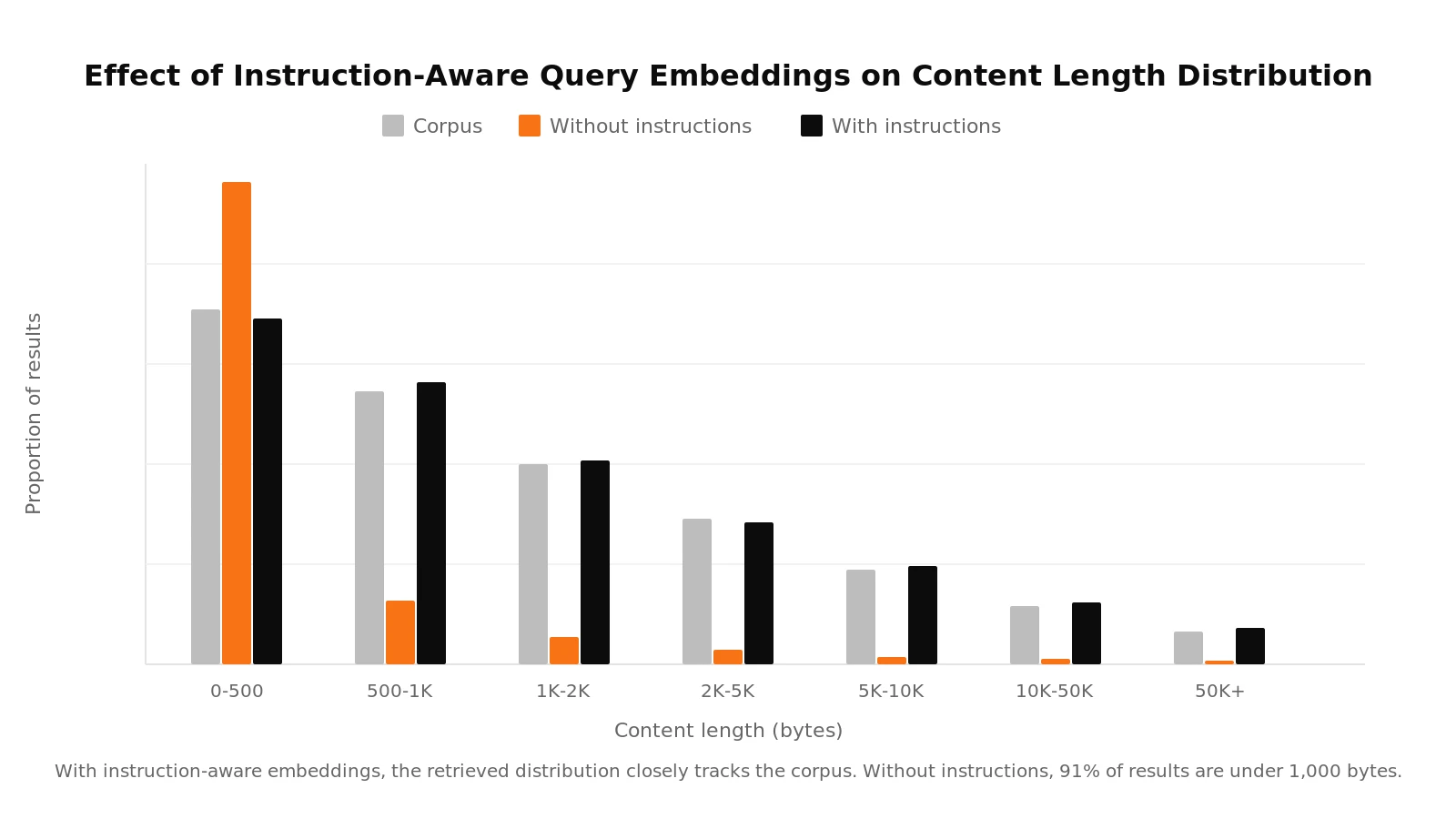
We had created two sets of query embeddings: one with the model's recommended instruction prefix and one without. Documents were embedded with the appropriate instruction prefix. The collapsed distribution came entirely from the queries without instructions.
This is a well-documented property of embedding models: without task-specific instructions, text length becomes a stronger signal in the vector space, and short queries cluster near short documents. The difference came down to a single line of configuration prepended to each query at embedding time.
With the instruction prefix, the content length distribution of retrieved documents closely matched the corpus.
We confirmed the impact with a controlled comparison. Adding instruction-aware embeddings cut the miss rate by more than a third and improved MRR across the board. That single line of configuration had a significant impact on retrieval quality, and without it, every downstream experiment would have been built on a misleading baseline.
Recall at Scale
With query embeddings verified, we moved to measuring how well the index itself performed.
We ran exact nearest neighbor (brute-force) search over the full corpus to establish ground truth, then compared it against ANN search with the same queries. Specifically, we measured recall@10: of the top 10 results returned by brute-force, how many does the ANN index recover?
At low search depths, the index was recovering less than half of the true top-10 neighbors. We collected the results and analysed them.
Our reaction was immediate: something was wrong with the index.
We spent time checking evaluation scripts, recalculating baselines, and looking for bugs. The evaluation pipeline and the data were sound. The search was returning the best results it could find. It just could not find the right ones.
To get a deeper understanding we started digging into the graph structure, and the issue became clearer. The index builds a navigable graph over the document vectors, where each document is a node connected to a limited number of neighbors. Search works by traversing this graph. Large parts of our graph were poorly connected. Many nodes had far fewer links than expected, making them effectively unreachable during search. From the perspective of a query, those documents did not exist.
Hoping for better results by rebuilding the graph
Two core index parameters controlled recall convergence: graph connectivity (the maximum number of links per node) and index build quality (the number of neighbors explored during insertion). Increasing these improves how well the graph is connected, but also increases indexing time and memory usage.
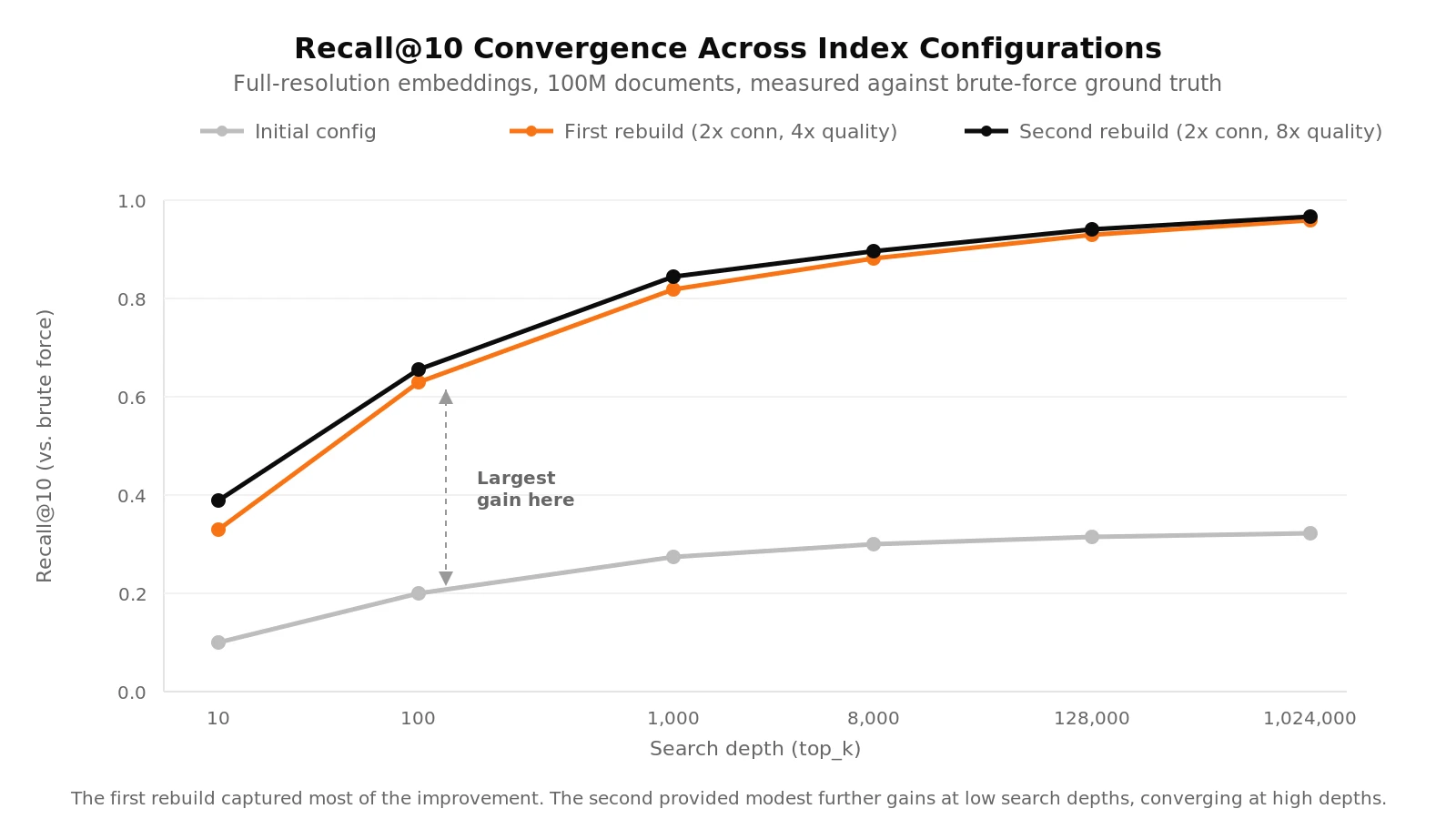
Initial configuration: The recall curve plateaued well below what brute-force could achieve, regardless of search depth.
First reindex: We doubled the maximum links per node and quadrupled the resolution. The improvement was dramatic. You could suddenly navigate to more neighbours in the graph, giving far better recall.
Second reindex: We doubled the resolution while keeping connectivity the same. The improvement was real but modest. At a search depth of 10, recall improved by about 6% over the first reindex. At a search depth of 100, about 2.5%.
Each reindex was all-or-nothing: no checkpointing, and each embedding type required its own pass.
The first rebuild captured most of the available recall improvement. The second confirmed where the diminishing returns start. The jump from "insufficient" to "adequate" was dramatic. The jump from "adequate" to "slightly better" was not.
The Latency Knee
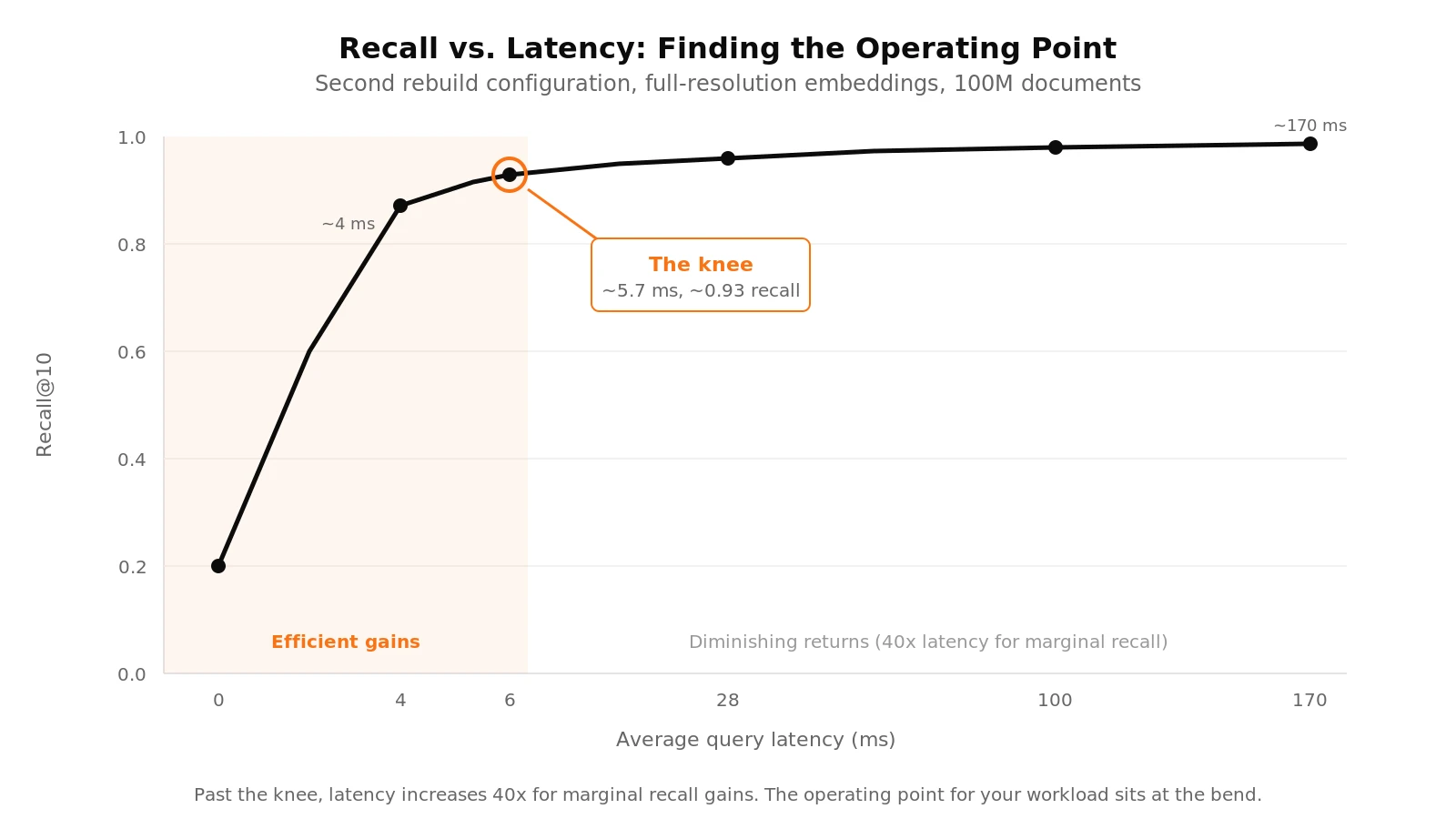
Higher recall requires deeper search, and deeper search costs latency. At moderate depths, the impact was small: a search depth of 100 produced average query latency of about 4 ms. At 8,000, latency rose to about 5.7 ms.
Beyond that, the curve steepened. At a search depth of 128,000, latency reached about 28 ms. At 1,024,000, roughly 170 ms per query. From the cheapest to the most expensive operating point, that is a 40x increase in latency, with most of the recall already captured in the lower range.
The knee of this curve is the operating point that matters. Past it, you pay significantly more compute for marginal recall improvements.
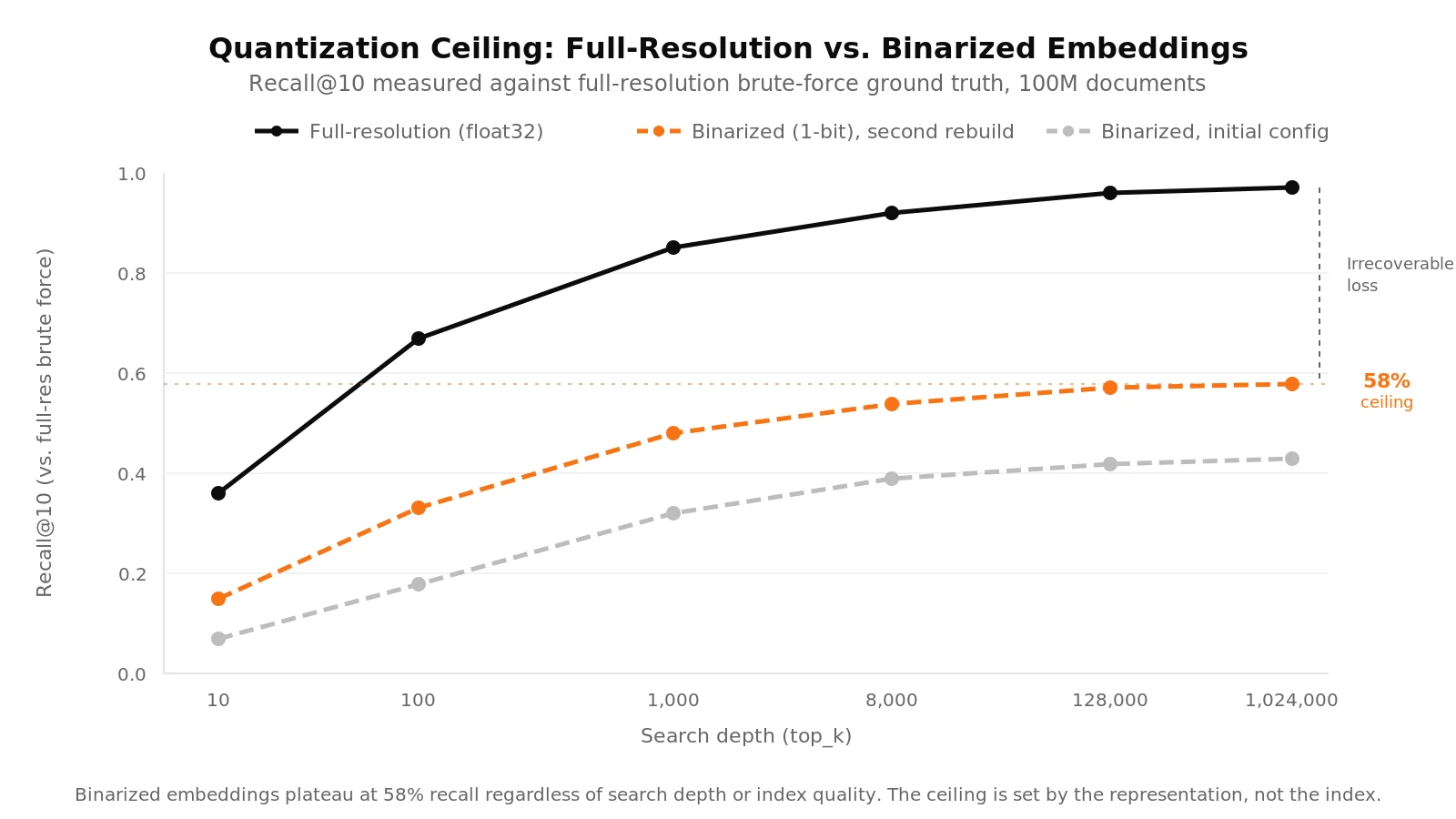
Quantization Sets a Hard Ceiling
We ran the same experiments with binarized embeddings, quantized from float32 to single-bit representation based on the sign of each dimension. Two questions we had in mind were: how well ANN approximates brute-force search (index quality), and how much information the embedding itself preserves (representation quality).
The result was stark. Comparing brute-force results between full-resolution and binarized embeddings revealed that the binarized version could recover at most 58% of the full-resolution top-10 neighbors. That is a hard ceiling. No amount of index tuning, no increase in search depth, can push past what the representation discards.
Within that ceiling, the behavior was consistent. Better graph connectivity produced similar relative improvements for both embedding types. But 58% recall was not usable for our purposes. Binarized embeddings save storage and can improve throughput, but the retrieval quality loss was too severe for our setup.
This matters for anyone making cost-performance tradeoffs in production. You should know where the quantization ceiling sits before committing to a representation. One way to find this is by measuring against full-resolution brute-force on your actual corpus.
The Interaction Problem
The biggest surprise was how much these components interact. Instruction-aware query construction, graph connectivity, and embedding resolution are not independent knobs. A problem in one can mask or amplify problems in the others. The only way we found to untangle them was to verify each layer independently before tuning the next.
If we hadn't checked the result length distributions first, the instruction prefix bias could have masked the graph connectivity issue or the low ceiling for quantized embeddings. Validating the index enabled us to rule out corpus-level issues: the low recall was due neither to missing preprocessing nor to a bad dataset, but to the low connectivity of the graph. And measuring against full-resolution brute-force revealed the quantization ceiling before we wasted reindex cycles trying to tune past it.
Agents issue more queries per task than humans, and each weak result compounds downstream. For retrieval systems that serve agents, not just humans, these interactions carry extra weight. OpenAI's BrowseComp-Plus benchmark, which measures an agent's ability to answer questions that require browsing the open web, found that retrieval quality is a primary constraint on task success. The interactions we saw here, between query construction, graph connectivity, and representation, are exactly the kind of failure modes that surface when agents stress a retrieval system.
Part 1covered the operational reality of building and iterating at this scale.
Part 3 will examine what happens when semantic and lexical retrieval are combined across different query types.
We're building Hornet for teams working on this problem. To be notified about new posts, benchmarks, and early product notes,